
One of the biggest topics I cover in this industry is the ability to propagate machine learning throughout every interface of compute that we work on. There are lots of ways to do that. You’ve seen or read my articles talking about anything from CPU to GPU to FPGA to ASICs. The thing is, those systems rely on an underlying platform to build on top of – whether that’s hardware, software, or everything else in between. Networking for example.
But how is that compute going to be consumed in the future? There are lots of different ways, and every company has their own way of doing it. I’ve covered a number of companies talking about how the core underlying architectures of those designs are not only transforming how we enable that compute, but also how we enable the agentic workflow coming down the pipe. There are lots of ideas in play here, and people are making really big bets on what works.
At the AI Infrastructure Summit earlier this year, I sat down with the CEO of NeuReality, Moshe Tanach, and SVP of Infrastructure at Arm, Mohamed Awad, to discuss how AI is coming along, and what the modular nature of the hardware is.
The following is a refined transcript from the fireside chat.
Ian Cutress: From your perspective, are we at a good place with AI right now?
Moshe Tanach: I think we are, and I think it’s going to get better. I think the proof is in the pudding – the industry is thriving. You see a lot of innovation that is just accelerating. S o, I think AI is starting to bring real value. Still a long way to come. I want to see the enterprise adopting it more and making bold decisions around this. In many of the customers, we see it is still in an experimental phase. But I think we’re in a good place.
Ian Cutress: We’ve got the guy from Arm right here!
Mohamed Awad: As the infrastructure person, and I think I broadly agree. I guess what I would suggest is that it’s really early days. We’re really just getting going. Architectures are still being sorted out. We’re trying to figure out how we are going to get efficient enough. We’re working on figuring out how we’re going to get enough power and enough performance. I think the aspirations for AI, the potential, is enormous. The entire industry is still trying to figure out how we meet that level of demand and enable AI to reach that potential. But from an investment perspective and a technology perspective, there’s a lot of amazing stuff happening right now, and so from that perspective, I think we’re in a really good place.
Ian: Obviously, both of you have to make big bets on where you think the market is going. There are billions of dollars of ideas out there. Sometimes I like to think of it as, “Is this a stable platform, or is this a very thin stand with a vase on top?” when you have to implement these ideas with your customers?
Mohamed: From our perspective, I believe the platform is incredibly stable. We’ve got literally all of the major hyperscalers investing in interesting platforms and strategies. You see a lot of the big technology providers doing similar investments. And then, on top of that, we see lots of emerging, interesting companies like NeuReality who are pushing the bounds of what’s possible and rethinking what those architectures look like. What’s interesting for me is that when I look at that, what I see is that you’ve got a lot of investment going into certain architectures and certain designs. But they are now being supported by lots of interesting innovation across the industry, which will allow us to leapfrog and really push the bounds of what’s possible moving forward. So, I definitely think there’s a lot of stability in terms of a great flow of interesting concepts and ideas coming through.
Moshe: Yeah. I think when you’re in a semiconductors, especially in a startup, every bet is big because it takes a year to three years to take it out to the market. But we‘ve talked about the modular approach. I think this is another tool to accelerate your development and to split the work and split the risk. Teaming up with Arm on the first generation was a big bet. We took the head node, and we fused the network function and the CPU function. And now the go-to-market is harder. The second generation that we announced about the AI SuperNIC is somewhat less difficult. It’s a smaller bet. We’re not betting on how it looks. We’re not betting on something that will need to convince the market. We’re betting on the highest end technology; we’re going 1.6 terabit when all the industry is going to introduce 800 gig. So, this is more of a technical challenge than a go-to-market challenge. But still, it’s a bet that you need to make when you’re in such an industry, unlike software, where you can try something, and after a quarter, you can pivot it right or left.

Ian: This is one of the conversations I have with companies at both ends of the scale is this idea of standardization versus individualization, and the value proposition that each company can bring. I think both of you end up on almost either side of that. How important are the standards to you?
Moshe: I’ve known Mohamed for many years. I was back at Marvell in 2012, and we built the first Arm server for storage. When you build infrastructure, when you build general-purpose solutions, you have to go standard. So, to me, it’s a way of life. The innovation and the differentiation come with the microarchitecture and the end-to-end system flows that you embed into what you build. But interfaces are always standard. We go with Arm because of the ecosystem that you get with it. It’s the Linux, the Kubernetes plugins, and everything above it. Optimization of libraries. So, I’m a sucker for standard and open source.
Mohamed: Yeah, I broadly agree. I think the way that we think about it is that it’s important to standardize where it makes sense, but allow room for innovation. If you look at what we’ve done with things like our compute subsystems, for example, where we’re pre-integrating, pre-verifying standard CPU IP blocks based on our Neoverse IP platform. That’s important because it allows partners to basically go off and add their own custom acceleration, which by definition is not standard. It allows them to go off and configure whatever interfaces they want and optimize that SoC to whatever level that they want for their particular use case or their particular workload.
If you look at what’s happening in the industry today, the reality is that most large-scale deployments are now being deployed based on complete rack designs which are completely optimized and are effectively non-standard. They’re being optimized for particular workloads and particular use cases. I think with the fullness of time, that’ll mature and they’ll become more standardized. But right now, that’s not the case.
I think over-standardizing too early could stifle innovation. But standardizing in the right places can actually accelerate innovation because it lowers the cost of deploying those custom solutions, and it also accelerates the time to market. The key for folks, whether it’s companies like NeuReality or companies like Arm, or a big hyperscaler or a big technology provider, is getting that balance right.

Ian: Has the market ever been this flush with ideas and enthusiasm ever before?
Mohamed: It’s always tough when you’re in the middle of it, but I have to tell you, it feels like the answer to that question is no. It feels like there’s a level of enthusiasm and excitement unlike really anything I’ve experienced, certainly to this level, in my career anyway. I’ve been around for a little bit. But, yeah, it’s definitely an interesting time, and I think the potential is undeniable, and that’s really what’s driving it. And certainly, the scale of investment is unlike anything we’ve seen before.
Ian: Moshe, you’re seeing the same level of enthusiasm regarding your ability to take stuff and go to market?
Moshe Tanach: Definitely, especially when you’re in a conference like this, and you see the level of innovation and the different techniques that people are trying to fix the memory bandwidth, or provide another software layer that simplifies deployment. So, I think for a startup in this market, there’s a lot of collaboration you can do with other big companies like Arm, and sometimes with startups, although it’s riskier to do that. For us, going down that path of building semiconductor solutions for this rack-scale design and coming from all angles around the GPU – just to keep it busy. That’s what our compass is. This is how we make the decisions on interfaces we adopt or the integration level. We went modular; there was a lot of discussion with Arm about potentially collaborating in the first generation. We just licensed the Neoverse N1 core, and we built a monolithic solution. Now, going modular, it opens opportunities to do all chiplets in NeuReality, or potentially collaborate with Arm on one of them. I think the future is fascinating, and more and more options are opening in front of us.
Ian : Has it been difficult to convince chip designers to go build a more modular chiplet design?
Moshe Tanach: No, I don’t think so. I think we see it as a vehicle to do more and to address more markets. The first one, going after the CPU market together with Arm cores, was opening a $65 billion opportunity for us, to 2030. Now, you go modular, and you address the NIC, which will be a component in the future AI CPU with the Neoverse V3 CSS – it opens another $35 billion market. So, it’s easy to explain to the innovators why splitting it into two and taking the challenge of this UCIe interface and making those two dies work as monolithic in terms of performance. But still, it’s easy to explain it to the engineers themselves.

Ian: Is there a market Moshe is not thinking about yet?
Mohamed: When you think about chiplets and semiconductor design more broadly, the fact is that it’s just getting more and more expensive. The cost to build a piece of silicon – and I’m sure an aggressive, efficient company like NeuReality can do it for less than this -but the fact is, on an advanced process node, it costs multiple hundreds of millions of dollars, probably approaching around $500 million, to take a piece of silicon to production from scratch.
When you think about the cost to tape-out a die, the verification cost, the design cost – the idea of amortizing that cost across multiple different designs is attractive. It’s attractive from a time-to-market perspective. It’s attractive from an investment perspective. And it lowers your risk. So, if you’re a startup, it means getting to market faster, more efficiently, and proving out your design. I think if you’re a larger, established company, it means being able to keep up or allocate resources to other places.
To come back to your question, well Moshe is a pretty bright guy! He’s probably thinking of more markets than I am. But I would suggest that having that flexibility is going to open opportunities. To think that we’ve got it all figured out here in September of 2025, given how early we are in this space, I think is probably naive.
Moshe: I couldn’t agree more. Another angle that we experience: hyperscalers that do their own chips, they think the same. For them, it also costs $300-$400 million for every product line that they open for themselves. So, engaging with a company like us for something that is not the most important thing for them to innovate on, and has less software above it, like a SuperNIC, opens opportunities for us because of the modular approach, because you’re trying to shorten that time to market.
At least one of the hyperscalers that talked to us tells us that he finds it’s very hard to grow organically and just recruit more engineers and train them on doing another type of chip or module. For them, I think the modular approach is good. Some people would say that everybody wants to keep their own investment and control all the pieces. But the reality is that time to market is more important, and gross margins are more important, and it opens opportunities for collaboration. I like it.
Ian: It’s interesting you both say that. Mohamed, I know from Arm’s perspective, you have multiple different IPs that you offer. But then you also have to go work with Cadence, Synopsys, the EDA tools, to be able to put that into either a monolithic or a chiplet form factor. And then beyond that, deal with the foundries. Has that gotten more complex now in this modular chiplet era?
Mohamed: Sure. It’s like the whole semiconductor industry has gotten more complex! That’s just one example of it. We’ve done certain things certainly within the infrastructure space to ease that burden. Ultimately, our goal is all about enabling and helping accelerate the design of these complicated systems. Whether that’s a company like NeuReality and Moshe and his team, helping them out, or it’s helping AWS and Google and Microsoft go build silicon and racks and systems in the way that they do. We focus on how to ease that and accelerate their time to market and lower their investment as much as possible.
One of the things that we did is we created this whole ecosystem: the Arm Total Design ecosystem. Arm Total Design is where we’ve taken our compute subsystems, where we’ve pre-integrated, pre-verified compute subsystems, and then we’ve made it available to a bunch of partners across the ecosystem so that they can leverage it to do pre-validation or pre-integration of IP. For example, partners like Synopsys and Cadence go and integrate memory controllers and PCIe controllers, so it’s all ready to go. Customers can take it, and they know that it just works.
We work with TSMC and Intel and Samsung who use that compute subsystem to do performance benchmarking on their process nodes – so they know that it’s going to perform well. We work with ASIC providers like Socionext, and even Broadcom, and others, who take our compute subsystems and can go off and build chiplets with it, or can at least verify and ensure that they’ve gone through the physical design flow. That means when a company comes to them and says, “Hey, we’re trying to build a new piece of silicon,” whether that’s a big established hyperscaler, a startup like NeuReality, or a complete new entrant to the market who maybe has a foundational model and wants to go build their own silicon, they are that much further down the path. From our perspective, has it gotten more complicated? Absolutely, but it’s just another day at the office.
Ian: All those things you mentioned sound like that $500 million has to come down.
Mohamed: That’s exactly the point. That’s exactly what we’re trying to do. We’re trying to drop that $500 million. We’re trying to accelerate it so that the design cycle isn’t three years or even 18 months. But how do we get it down to 12 months? How do we get it down to just six months? There’s a long way to go to get there, but that’s what we’re trying to do.
Moshe: It will come on the account of the cost of the product eventually. Just like HBM in GPUs, you now have another player on the supply chain to the customer taking more gross margins on every HBM piece. In that case, you shorten the time to market, you lower the cost of the development, but you make the product more expensive. In some cases, it will not work. In our case, the data center market, where it’s thriving now, makes the most sense.

Ian: In your roadmap, we’ll show a picture of it, right at the end you’ve got the NR2 – your next generation AI chip – in there, using Neoverse V3. What does that enable, because you’ve gone from a Neoverse N1 to a Neoverse V3? That’s quite a big jump.
Moshe: When we started, the whole idea was to bring the most efficient head node for inference. When we’re looking forward to where the AI head node needs to evolve to serve training, inference, and the ever-evolving software frameworks that are coming out, if I had a magic stick that changed NR1 to have 32 cores, I would do it today. So, for the next generation, it was obvious we needed something more powerful. When we chose the Neoverse N1, there wasn’t a V series; it came after.
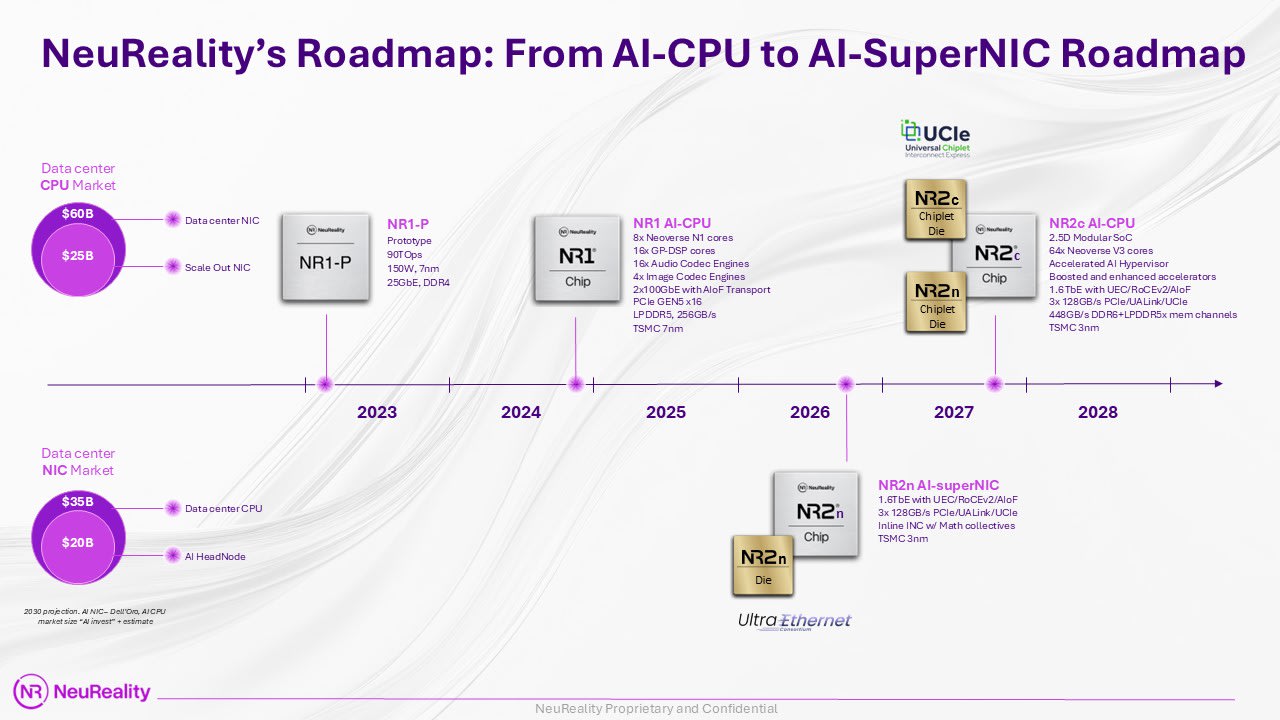
It was an obvious decision for us to go with Neoverse V3 CSS. It opens the opportunity again to use the modular approach and have 64 cores per position or 128 cores. But this is going to come in the compute die. The first die we’re focusing on is the SuperNIC. We’re going to productize it, sell it as a module, as a die, as a PCIe card. And then we’ll do the compute with a Neoverse V3, couple it with the SuperNIC, as the second generation of the complete AI head node.
What it more opens is access to our customers to enjoy all the ecosystem investment that Arm is doing, and that all the hyperscalers are doing. There’s a lot of innovation and investment around software on Arm, and when you’re aligned to the top of the line Neoverse V3, you can enjoy all of it. It means an easier deployment process for our customers. We talked about it earlier; it’s a very important thing for the customer.
Ian: Mohamed, I’ve been tracking your Neoverse platform since its inception, and the amount of players who have adopted – multiple times. You’ve got a long list of Neoverse V3 players who have taken this core, taken the design, and deployed it. What are they asking for next?
Mohamed: I think it’s more of what we’re describing, which is just an accelerated path towards getting to market is the big thing. The pace at which this industry is moving is phenomenal. And so, I think that is one. I think the second is about performance per watt.
It’s interesting because back when Neoverse first launched, in 2019 or 2020, AI systems were one CPU to eight GPUs or eight accelerators; that was the state-of-the-art. Now, we’re talking about one CPU to two accelerators. The reason for that is because all of the management of the software that’s driving these infrastructure ecosystems is all happening on the CPU. The accelerator is there, and there’s a tremendous amount of heavy lifting that’s happening there in terms of the matrix multiplication, but a lot of that software stack is actually running on the CPU.
In efficiency, our ability as an industry to keep up from a power perspective, is tough. We’ve got people building nuclear power plants and talking about putting data centers in space, just to keep up. Another way you keep up is you get more efficient; you get better perf per watt. So, when you start talking about a CPU platform that’s optimized for AI that’s giving you 40%, 50%, 60% better perf per watt than legacy architectures – what our customers ask for more than anything, is more of that. More. Of. That.